
300x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 알고리즘
- 브루트포스
- AI
- 코딩테스트
- 동적 프로그래밍
- 프로그래밍
- 프로그래머스
- 동적프로그래밍
- PYTHON
- CSS
- 코딩 테스트
- 코딩
- DFS
- 리눅스
- google coding competition
- BFS
- nlp
- 운영체제
- 킥스타트
- linux
- 파이썬
- kick start
- 순열
- dp
- OS
- 그래프
- 구글 킥스타트
- 네트워크
- 백준
- 딥러닝
Archives
- Today
- Total
오뚝이개발자
[DB] CH11. 인덱싱(Indexing) 본문
728x90
300x250
DB에서 Indexing 왜 쓰는가?
- data access를 효율적으로 하기 위해(searching)
- 좀 더 구체적으로 설명하자면, index file을 위한 저장공간은 record file에 비해 비교적 작다. 비록 어떤 relation을 저장하는 데이터가 10개의 block에 걸쳐 저장되어 있다해도 index file은 1개 정도의 block에 저장 가능하다. 만약 이 같은 index를 이용하지 않으면 검색을 위해 10개의 block을 모두 찾아보아야 한다.
Search key란?
- file내의 record를 찾기 위한 set of attribute
- index file은 search key와 pointer로 구성됨
Index를 크게 두 가지로 분류하면?
- Ordered index : index entry가 search key value 순으로 정렬된 것
- Hash index(Unordered) : ordered index의 반대
Indexing의 구분
- ordered
- primary index(clustering index) : index 내의 search key order = file 내의 record order(file에 record가 저장된 순서대로 index 내 search key 저장)
- secondary index(non-clustering index) : index 내의 search key order가 file 내의 record order와 다른 경우(단, index내의 search key는 정렬되어 있어야 함)
- secondary index는 dense index여야 한다.
- unordered
- dense index : index내에 file 내의 모든 record에 대한 search key가 존재
- sparse index : index내에 file 내의 일부 record에 대한 search key가 존재




Sparse index의 장단점
- 장점
- 적은 space overhead
- insertion/deletion시 index maintaining에 드는 비용이 적다.
- 단점
- index에 없는 record에 대한 접근이 dense index에 비해 느리다.
Multi-level index를 사용하는 이유
- primary index가 너무 커져서 access 비용이 증가하는 것을 막기 위해
Multi-level index의 구조
- outer index : sparse index of inner index
- inner index : primary index
Multi-level index의 단점
- record 접근을 위해 추가적인 indirection을 거쳐야 함
- insertion/deletion시에 모든 level의 index들이 update되어야 함
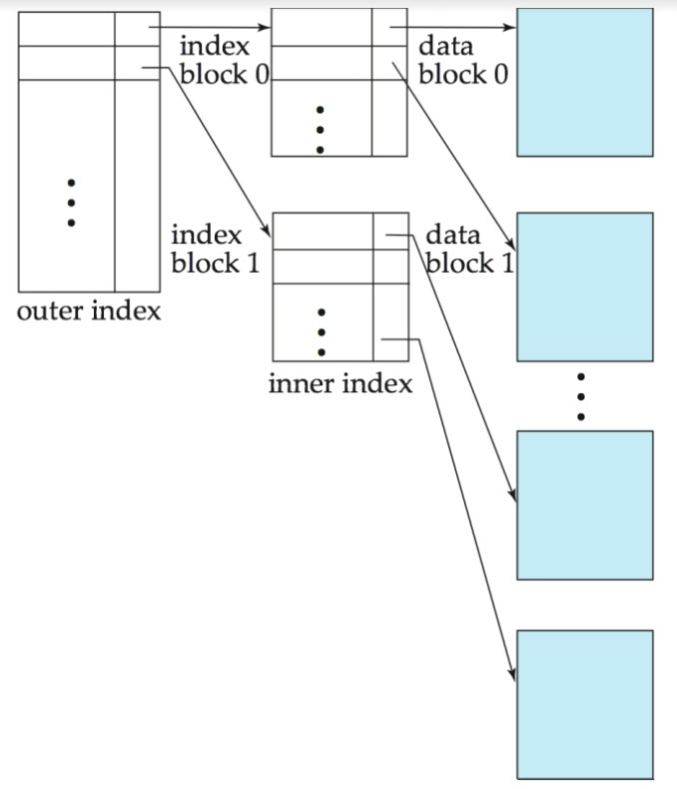
Secondary index를 왜 쓰는가?
아래와 같은 경우에 Secondary index는 위력을 발휘한다.(위에 첨부한 그림을 보면 이해에 도움이 된다.)
- 특정 value를 가진 데이터들에만 참조할 때(ex. instructor에서 dept_name이 "Biology"인 경우만 참조)
- 특정 range의 값들을 참조할 때(ex. instructor에서 salary가 8000이하인 것들만 참조)
단순히 sequential scan을 할 땐 primary index가 efficient
B+ tree의 도입 배경
B+ tree는 indexed-sequential file의 다음과 같은 단점을 극복하기 위해 도입되었다.
- 데이터가 증가할 수록 overflow block으로 인한 성능 저하
- "전체"에 대해 주기적인 reorganization을 해주어야 함
cf) indexed-sequential file : ordered sequential file with a primary index
B+ tree의 장단점
- 장점
- insertion/deletion 시에 "전체"가 아닌 small, local change만 발생
- insertion/deletion 시에 자동적으로 reorganize
- BST처럼 탐색할 범위를 줄여준다
- 데이터가 많아도 상대적으로 빠르게 search할 수 있다.(ex. 1000000개의 search key value가 있고 n=100인 B+ tree라해도 최대 hegiht는 4이므로 최대 4개의 노드만 탐색하면 된다.)
- 단점
- 포인터를 위한 space overhead
- insertion/deletion 시에 추가적인 구조 변경에 따른 overhead
- 하지만 장점이 단점을 상회하므로 많이 사용한다
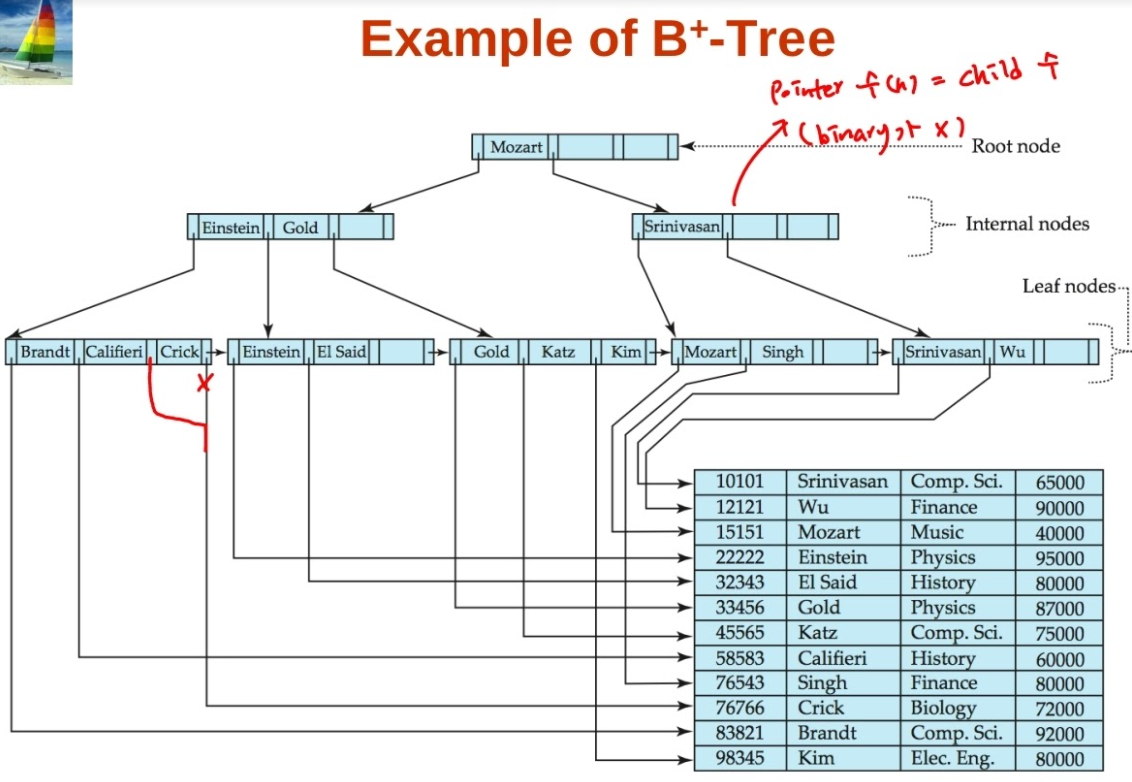
B+ tree의 분류
- B+ tree는 multi-level index이면서 dense index(leaf node의 경우), sparse index(internal node의 경우)
728x90
300x250
'CS 기초 > DB' 카테고리의 다른 글
| [DB] CH15. 동시성 제어(Concurrency control) (0) | 2020.11.06 |
|---|---|
| [DB] CH14. 트랜잭션(Transaction) (0) | 2020.11.06 |
| [DB] CH11. 해싱(Hashing) (0) | 2020.11.03 |
| [DB] CH10. 스토리지와 파일 구조(Storage & File structure) (0) | 2020.11.03 |
| [DB] CH8. 관계형 데이터베이스 디자인(Relational DB Design) - good form이란? (0) | 2020.11.03 |
'CS 기초/DB' Related Articles
more




Comments