
300x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 코딩
- 코딩테스트
- 프로그래머스
- BFS
- 동적 프로그래밍
- 프로그래밍
- linux
- 파이썬
- 순열
- PYTHON
- 알고리즘
- 브루트포스
- 킥스타트
- 운영체제
- dp
- google coding competition
- 구글 킥스타트
- 동적프로그래밍
- 그래프
- 코딩 테스트
- kick start
- OS
- 딥러닝
- 리눅스
- AI
- nlp
- DFS
- 네트워크
- 백준
- CSS
Archives
- Today
- Total
오뚝이개발자
NLG(Natural Language Generation)에 대하여 본문
728x90
300x250
Sub-tasks of NLG
- Machine Translation
- Summarization
- Dialogue : task-oriented system, open-domain system(social dialogue)
- Creative writing : storytelling, poetry-generation
- Freeform Question Answering
- Image captioning
Language Model(LM)
- Language Modeling : 특정 time-step까지의 words sequence가 주어졌을 때, 해당 time-step 이후의 word를 predict하는 것
- Language Model : 확률 분포 P(yt|y1,...,yt-1)를 producing하는 system
- Conditional Language Modeling : LM과 유사하나, 주어진 input이외의 또 다른 input x를 받아 확률 분포 P(yt|y1,...,yt-1,x)를 produce
- Conditional Language Modeling Example(input x, output y)
- Machine translation : x = source sentence, y = target sentence
- Summarization : x = input text, y = summarized text
- Dialog : x = dialogue history, y = next utterance
How to generate text??
Q) How to literally "generate text" from trained LM?
A) LM의 각 step에서의 prediction result는 다음에 올 단어에 대한 확률 분포 vector 표현이다. 바로 이 확률분포로부터 다음에 올 word를 결정해야 한다. 이 때 사용하는 것이 Decoding Algorithms이다!
Decoding Algorithms 1 : Greedy decoding
- Similar to "Greedy algorithm"
- 단순히 각 step에서의 확률분포 결과에서 maximum probability value를 갖는 word는 select
- 매 시점마다 해당 시점만을 기준으로 최선(최적)의 결정을 내리기 때문에 backtracking을 할 수 없다 → 출력 시퀀스에 오류를 포함하기 쉽다는 단점 有, 전반적인 context를 고려한 결과 X

Decoding Algorithms 2 : Beam search
- Greedy decoding의 대안!
- 매 시점마다 확률값이 가장 높은 하나의 단어만 고려하는 대신 높은 확률값을 갖는 단어들의 후보군을 만들어 모든 후보군들을 동시에 tracking함 (여기서 후보군의 수는 hyper-parameter)
- 단순히 특정 단어의 확률값을 참고하는 것이 아니라 부모로부터 뻗어나온 갈래의 누적확률을 고려!!(아래 그림의 수식 참고)
- beam size k의 영향
- Low k → greedy decoding과 유사해짐, More on-topic but nonsensical
- High k → greedy decoding의 문제점 해결. Safe and correct response but less relevant(generic) 지나치게 큰 k 값은 오히려 BLEU 점수 감소를 야기.
- Good generation ↔ Computing cost (Trade-off)


Decoding Algorithms 3 : Sampling-based decoding
- Beam search에서 high k(beam size)를 갖더라도 너무 generic하지 않도록 할 수는 없을까?
- LM decoder의 예측 확률분포로부터 sampling을 통해 매 step 출력 단어를 결정(Greedy decoding과 유사해보이지만, argmax가 아니라 sampling을 사용)
- BUT 너무 랜덤하게 샘플링하면 문제가 생길 수 있으니 top-n의 단어로 제한해 샘플링하기도 함
- Pure sampling
- step t에 확률분포로부터 이후 단어를 랜덤하게 추출
- Top-n sampling
- pure sampling처럼 완전 random하게 sampling하지 않고, 특정 time step에 확률이 가장 큰 top-n개의 단어들 중 sampling
- hyper-parameter로 n을 정해줘야 함
- Large n → diverse but risky output
- Small n → safe but generic output

Decoding Algorithms 4 : Softmax temperature
- Scaling factor인 를 사용

- lower → 단어 출현 확률분포를 첨예하게 만듦(spiky distribution, output focused on some specific words)
- raise → 단어 출현 확률분포를 고르게 만듦(uniform distribution, diverse output)
- 엄밀히 말하면, decoding algorithm은 아니고 decoding algorithm과 함께 쓰이는 기법으로 단어 선택에 대한 확률분포의 range를 조정하는 방법
NLG task 1 : Text summarization
- 어떠한 text x가 주어졌을 때, 그것의 주요 정보는 포함하면서 길이는 더 짧은 y라는 요약문을 generate하는 task(input x에 대해 summary y를 generate하는 task)
- 하나의 document를 summary하는 single-document summarization과 여러 document의 정보를 통합해 하나로 summary하는 multi-document summarization이 있다.

2가지의 summarization 전략(=How to generate summary)
- Extractive summarization
- original text로부터 몇 개의 문장을 추출해 summary 생성, 주로 pre-neural 시대에 사용했던 방법
- Easier, Restrictive(no paraphrasing)
- Abstractive summarization
- NLG를 사용해 새로운 summary text를 생성
- More difficult, More flexible(human-like)
NLG task 3 : Dialogue(흔히 접할 수 있는 것이 챗봇)
- Pre-neural 시대
- 주로 predefined response template을 사용 혹은
- 코퍼스로부터 적절한 반응들을 검색(retrieve)하여 뽑아 쓰는 방식으로 response
- 이후 seq2seq + attention 기반 모델들을 사용하는 시스템이 연구되어 왔고, 이를 시작으로 점차 open-ended한 반응을 generate하는 쪽으로 발전됨.
- Task-oriented dialogue system
- Assistive (customer service, recommendation, question&answering)
- Co-operative (two agents solve a task together thru dialogue)
- Adversarial (two agents compete in a task thru dialogue)
- Open-domain dialogue system(=Social dialogue system=Open-ended dialogue system)
- Deal with a lot of topic, more general than task-oriented dialog system
- Chit-chat(various topic)
- Human mental care(just like movie "HER")
비교적 최근에 나온 몇 가지 Dialog system 예시
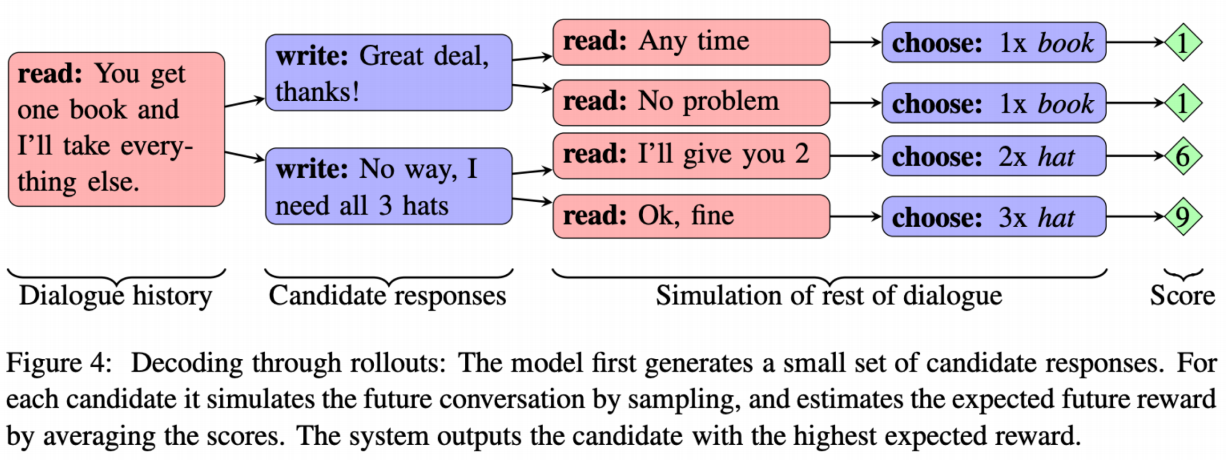
1. Negotiation dialog
- "Deal or No Deal? End-to-End Learning for Negotiation Dialogues", Lewis et al, 2017
- Tow agents negotiate how to divide a set of items → The agents have different value functions for items → The agents talk until they reach an agreement

2. Conversational question answering(CoQA)
- "CoQA : a Conversational Question Answering Challenge", Reddy et al, 2018
- Answer questions about a piece of text within the context of a conversation
- Answers must be written abstractively not just copied
- QA task + Reading comprehension task + Dialog task
- 이처럼 Dialog는 다른 task들과 혼합되어 사용될 경우 더 큰 효과를 얻어낼 수 있음

Dialog system의 몇 가지 문제점(Deficiency)
- Generic or boring responses
- Solution1 : Test-time fixes
- Beam search 동안 rare한 words를 directly upweight
- Beam search 대신 sampling-based decoding을 사용
- Solution2 : Conditioning fixes
- 추가적인 contents에 대해 decoder를 조정(condition) (e.g. 몇 개의 content words를 sampling하고 거기에 집중)
- 완전한 generate-from-scratch model보다 retrieve-and-refine model을 설계해 train
- 예) corpus를 human-written utterance로 구성해 여기서 sampling을 해 현재의 scenario에 맞게 조정
- Solution1 : Test-time fixes
- Irrelevant responses : generate unrelated responses to user's utterance
- Too generic한 응답을 생성하거나 unrelated한 subject로 주제를 바꾸는 경우
- Solution : optimize for MMI(Maximum Mutual Information)"A Diversity-Promoting Objective Function for Neural Conversation Models", Jiwei et al, 2016
- MMI를 objective function으로 사용, S는 source sentence T는 target sentence
- target 문장이 다른 조건 없이 자체적으로 출현할 확률(log(p(T))을 penalty로 추가해 S 없이도 자주 출현하는 문장보다는 자체 출현확률은 낮지만, 그에 비해 S가 조건부로 들어왔을 때 출현확률이 높은 문장을 높게 평가할 수 있게 된다. → Generic한 response를 output으로 내는 것을 방지할 수 있다!!

- Repetition
- Solution1(simple) : beam search 과정에서 repeating words를 directly block시킴
- Solution2(complex) : coverage mechanism을 통해 attention mechanism이 동일한 단어를 반복적으로 주목하는 것을 방지
- Solution3 : Repeated words에 penalty를 부여하도록 objective function을 설계
- Lack of consisten persona
- "A persona-based neural conversation model", Li et al, 2016
- Dialog model이 conversation partner의 persona를 encode하는 법을 학습해 embedding →발화들이 이렇게 embedding된 persona condition에 부합하게 생성됨
- Lack of context(not remembering conversation history)
NLG task 3 : Storytelling
- Storytelling의 대표적인 task
- Generate a story given an image
- Generate a story given some keywords(or short paragraph)
- Generate the next story given previous story(Continuation)
- 비교적 최근에 급부상된 NLG 분야
- The first storytelling workshop was held in 2018
- Storytelling이 직면한 Challenges
- Fluent, Quite related to given source, Diverse(non-generic), Dramatic story
- But!!! Meaningless, No plot, No coherence → 상황이나 분위기, 감정에 대한 단순한 묘사가 대부분
- 원인 : 언어 모델은 word sequence에 기반해 text를 생성. BUT story라는 것은 사실상 event들의 sequence인 셈
- event2event story generation model("Strategies for Structuring Story Generation", Fan et al, 2019)
- 향후 갖추어야 할 부분
- 사건에 대한 개념 + 사건들 간의 인과관계
- 등장인물에 대한 개념 + 그들의 personality + 인물의 history + 타인물들과의 관계성
- 세계관 : 갖고 있는 지식이나 관점을 기반으로 어떻게 세상(물론 스토리 속 세상)을 이해할 것인지
- 좋은 story telling 원칙(혹은 구조적인 이야기 서술 기법, plot을 구성할 수 있도록)
728x90
300x250
'AI > Deep Learning Paper Review' 카테고리의 다른 글
| Towards a Human-like Open-Domain Chatbot(Meena) 리뷰 (0) | 2021.11.04 |
|---|---|
| ELECTRA(ICLR 2020) 논문 리뷰 (1) | 2021.10.27 |
| BERT(NAACL-HLT 2019) 논문 리뷰 (0) | 2021.10.08 |
| Attention is all you need(NIPS 2017) 논문 리뷰 (0) | 2021.09.17 |
| RealFormer : Transformer Likes Residual Attention 논문 리뷰 (0) | 2021.09.12 |
'AI/Deep Learning Paper Review' Related Articles
more




Comments