
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- CSS
- 코딩 테스트
- linux
- dp
- 알고리즘
- 운영체제
- 브루트포스
- 그래프
- 코딩
- 파이썬
- 딥러닝
- 네트워크
- AI
- 동적프로그래밍
- kick start
- DFS
- google coding competition
- 동적 프로그래밍
- 프로그래밍
- 구글 킥스타트
- 리눅스
- OS
- 백준
- 킥스타트
- 프로그래머스
- nlp
- PYTHON
- 코딩테스트
- 순열
- BFS
- Today
- Total
오뚝이개발자
오버피팅(overfitting) 방지법 정리 본문
오버피팅이란?
훈련 데이터에만 지나치게 학습되어 새로운 데이터에 대응하지 못하는 현상, 과적합이라고도 한다.
주로 다음과 같은 경우에 발생한다.
- 모델이 깊어 파라미터 수가 많고, 표현력이 좋은 모델
- 학습용 데이터의 양이 부족한 경우
SOL1) 배치 정규화(Batch Normalization)
- 일반적으로 좋은 가중치의 초깃값이란 활성화 값(Activation value)이 고르게 분포되도록 하는 값을 말함.
- 배치 정규화는 가중치의 초깃값에 의존하지 않고 '강제로' 활성화 값을 적절히 분포되도록 하는 것.
- 미니배치 B=x1, x2, ..., xn을 평균이 0, 분산이 1인 표준정규분포를 따르도록 정규화
- 배치 정규화의 장점
-
가중치 초깃값에 크게 의존적이지 않다.
-
Gradient vanishing/exploding 방지
-
오버피팅 억제
SOL2) 일반화(Regularization)
- regularization은 신경망이 범용성을 갖도록 함.(앞서 언급된 Normalization과는 다름!)
- regularization에는 다음과 같은 것들이 있다.
-
Weight decay(L2 regularization)
-
Dropout
-
Hyperparameter optimization
-
Data augmentation
SOL2-1) Weight decay(L2 regularization)
- L2 regularization은 가장 일반적인 일반화 기법
- overfitting은 일반적으로 가중치 값이 커서 발생하는 경우가 많으므로, 가중치 값이 클수록 큰 페널티를 부과해 과적합 억제함.
- 가중치 각각의 Loss function에 1/2 * λ * W^2을 더하는 방식으로 페널티 부과
- λ는 weight decay의 강도를 조절하는 하이퍼파라미터로, 크게 설정할수록 큰 weight penalty를 부여
- Loss function에 1/2 * λ * W^2을 더하는 것이 어떻게 페널티를 부과하는 게 될까?
- Loss function에 1/2 * λ * W^2을 더해주므로 gradient descent 과정에서 이를 미분한 λ * W를 더해주게 됨.
- 이에 따라 가중치는 W ←W −η( ∂L /∂W + λW )으로 갱신되므로 weight값은 그만은 보정됨.(η:학습률)
- Loss function에 λ | W | 를 더하는 sparsity(L1 regularization)도 있으며 L1, L2 regularization을 동시에 적용 가능
- 하지만 일반적으로 L2 regularization만을 사용하는 것이 더 좋은 결과를 냄.
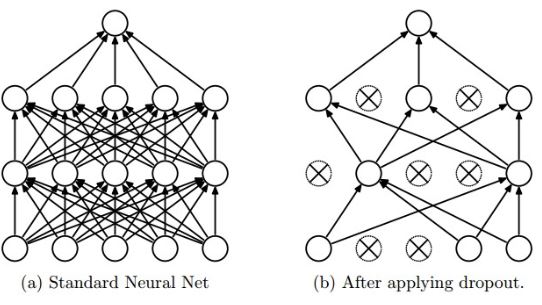
SOL2-2) Dropout
- L1, L2 reularization과 상호보완적인 방법
- Dropout은 훈련 시에 각 계층마다 일정 비율의 노드를 임의로 선택해 weight parameter update시 누락시켜 진행하는 방법
- 네트워크 내부에서 이루어지는 앙상블 학습 방법 중 하나로 생각해도 됨.
- 앙상블 학습은 개별적으로 학습시킨 여러 모델의 출력을 종합해 추론하는 방식
- 앙상블 학습은 여러 네트워크를 개별적으로 학습시키고, 같은 입력을 주어 나온 출력값의 평균을 구해 가장 큰 평균값을 갖는 것으로 추론을 해 전체 모델의 정확도가 향상되는 효과
- Backpropagation시에 connention이 끊어진 노드는 weight parameter update가 수행되지 않음.
- Forward pass는 일반적인 경우처럼 시행
- 단, test과정에선 모든 노드에 일반적인 경우와 같이 모두 신호가 전달되어야 함.
SOL2-3) Hyperparameter optimization
- 하이퍼파라미터 최적화는 대략적인 범위를 설정하고, 그 범위에서 무작위로 값을 선택해 정확도를 평가한 후 좋은 정확도를 내는 쪽으로 범위를 축소하는 방식을 반복함
- 이후 어느 정도 범위가 좁혀지면 그 범위 내에서 값을 하나 골라냄
- 일반적으로 규칙적 탐색보다는 무작위 샘플링이 더 좋은 결과를 낸다고 함.
- 하이퍼파라미터 최적화에 test data set을 사용하면 하이퍼파라미터의 값이 test data set에 오버피팅될 수 있으므로 validation set을 따로 쓰는 것이 좋다.(일반적으로 test data set의 20%를 추출)
SOL2-4) Data augmentation
- 학습용 데이터가 적을 때, rotate/flip/crop/shift/partial masking/HIS distortion 등을 적용해 데이터셋을 확장시키는 방법
- 간단하지만 효과가 매우 좋음
출처
'AI > 밑바닥딥러닝1' 카테고리의 다른 글
| Bias와 Variance (0) | 2020.07.06 |
|---|---|
| L1, L2 regularization (0) | 2020.06.28 |
| [CH8] 딥러닝 (0) | 2020.06.23 |
| [CH7] 합성곱 신경망(CNN) (0) | 2020.06.23 |
| [CH6] 학습 관련 기술들 (0) | 2020.06.21 |



