
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- CSS
- OS
- 동적프로그래밍
- kick start
- 코딩
- nlp
- 구글 킥스타트
- 딥러닝
- 리눅스
- 코딩 테스트
- 프로그래머스
- 그래프
- linux
- DFS
- dp
- 백준
- 운영체제
- 킥스타트
- google coding competition
- 브루트포스
- BFS
- 코딩테스트
- PYTHON
- 프로그래밍
- 네트워크
- AI
- 동적 프로그래밍
- 알고리즘
- 파이썬
- 순열
- Today
- Total
오뚝이개발자
[OS]CH10. 가상 메모리 관리(Virtual memory management) 본문
가상 메모리 관리의 목적
-
page fault rate를 최소화해 시스템 성능 최적화
reference bit(=used bit)란?
-
캐시나 페이지에서 최근에 참조되었는지 여부를 나타내는 bit
-
참조되면 1로 설정
-
주기적으로 0으로 초기화
-
locality에 기반한 정보(최근 참조된 것들 확인 가능)
update bit(=dirty bit=modified bit=write bit)이란?
-
캐시나 페이지에서 갱신되었는지 여부를 나타내는 bit
-
만약 page에서 update bit=1면 해당 page의 (main memory상 내용) != (swap device상 내용)
-
변경된 내용을 swap device에 write-back해주는 작업이 필요(for 데이터 무결성)
-
update bit는 write-back 후 0으로 초기화
Demand paging vs. Pre-paging
-
둘은 특정 page를 메모리에 언제 적재할 것인가에 관한 전략
-
Demand paging(Demand fetch) -> 대부분의 시스템이 사용
-
프로세스가 참조하는 페이지들만 메모리에 적재
-
page fault overhead가 존재
-
-
Pre-paging(Anticipatory fetch)
-
가까운 미래에 참조될 가능성이 높은 페이지를 예측해 메모리에 적재
-
예측 성공 시, page fault overhead가 없음
-
하지만 실패 시, 불필요한 메모리 적재로 인한 자원 낭비
-
예측으로 인한 prediction overhead
-
Placement strategy(배치전략)이란?
-
프로세스를 메모리의 어느 공간에 적재할 것인가에 관한 전략
-
배치기법
-
First-fit
-
Best-fit
-
Worst-fit
-
Next-fit
-
Replacement strategy(교체전략)이란?
-
빈 공간이 없는 경우 새로운 페이지를 어떤 페이지와 교체할 것인가에 관한 전략(cache에 관해서도 적용가능)
-
Fixed allocation 기반 기법
-
MIN(OPT) algorithm
-
Random algorithm
-
FIFO algorithm
-
LRU algorithm
-
LFU(Least Frequently Used) algorithm
-
NUR(Not Used Recently) algorithm
-
Clock algorithm
-
Second chance algorithm
-
-
Variable allocation 기반 기법
-
VMIN(Variable MIN) algorithm
-
Working Set algorithm
-
PFF(Page Fault Frequency) algorithm
-
Cleaning strategy(Write-back strategy)란?
-
변경된 페이지를 언제 write-back할 것인가에 관한 전략(언제 dirty bit를 clean할지)
-
Demand cleaning vs. Pre-cleaning
-
Demand cleaning : 해당 page가 메모리에서 내려올 때 write-back(대부분의 시스템이 사용)
-
Pre-cleaning(Anticipatory cleaning) : 더 이상 변경될 가능성이 없다고 판단되면 미리 write-back
-
Multi-programming degree 결정(Load control strategy)
-
(multi-programming, throughput) 그래프에서 throughput이 plateau로 유지되는 영역이 적당
-
저부하(under-loaded) : 시스템 자원 낭비, 성능 저하
-
고부하(over-loaded) : 자원경쟁 심화, 성능 저하, 스레싱(thrashing) 발생
-
스레싱 : 자원에 비해 다중 프로그래밍 정도가 과도하게 높아질 때 page fault가 많이 발생해 성능이 저하되는 현상
교체전략 중 MIN(OPT) 알고리즘이란?
-
앞으로 가장 오랫동안 참조되지 않을 페이지 교체(optimum)
-
비현실적(페이지 참조 정보를 미리 알고 있어야 함)
-
But 최적해로서 교체기법의 성능 평가 도구로 사용 가능
교체전략 중 FIFO 알고리즘(Belady's 알고리즘)이란?
-
적재된 지 가장 오래된 페이지를 교체(먼저 들어온 것)
-
단점
-
페이지가 적재된 시간을 기억하고 있어야 함
-
자주 사용되는 페이지가 교체될 가능성이 높음(=locality에 대한 고려가 없음)
-
FIFO anomaly : FIFO 알고리즘 사용 시 더 많은 page frame을 할당해주었음에도 불구하고 page fault 수가 증가하는 경우(자원을 더 줬는데 성능은 낮아지는 경우) -> locality를 고려하지 않아서 생기는 문제
-
교체전략 중 LRU 알고리즘이란?
-
가장 오랫동안 참조되지 않은(최근에 가장 덜 사용된) 페이지를 교체
-
Locality를 고려한 알고리즘(MIN 알고리즘에 근접한 성능) -> 실제로 가장 많이 사용
-
단점
-
참조 시마다 시간을 기록해야 함 - 간소화해 순서를 기록하는 것으로 대체 가능
-
loop 실행에 필요한 크기보다 작은 수의 page frame이 할당된 경우, page fault가 급격히 증가(ex. Loop를 위한 |ref. string|=4, 할당된 pf=3) -> allocation 기법에서 해결해야 함
-
교체전략 중 LFU(Least Frequently Used) 알고리즘이란?
-
가장 참조횟수가 적은 페이지를 교체
-
locality 반영
-
단점
-
참조 시마다 참조 횟수 카운트해야 함(overhead)
-
최근 적재된 참조될 가능성이 높은 페이지가 교체될 가능성이 있음
-
교체전략 중 NUR(Not Used Recently) 알고리즘이란?
-
Reference bit(r), Update bit(u)를 사용해 교체할 페이지를 고르는 것
-
교체순서(r,m) : (0,0) -> (0,1) -> (1,0) -> (1,1)(참조 안 된 것 r=0 우선적으로 선택)
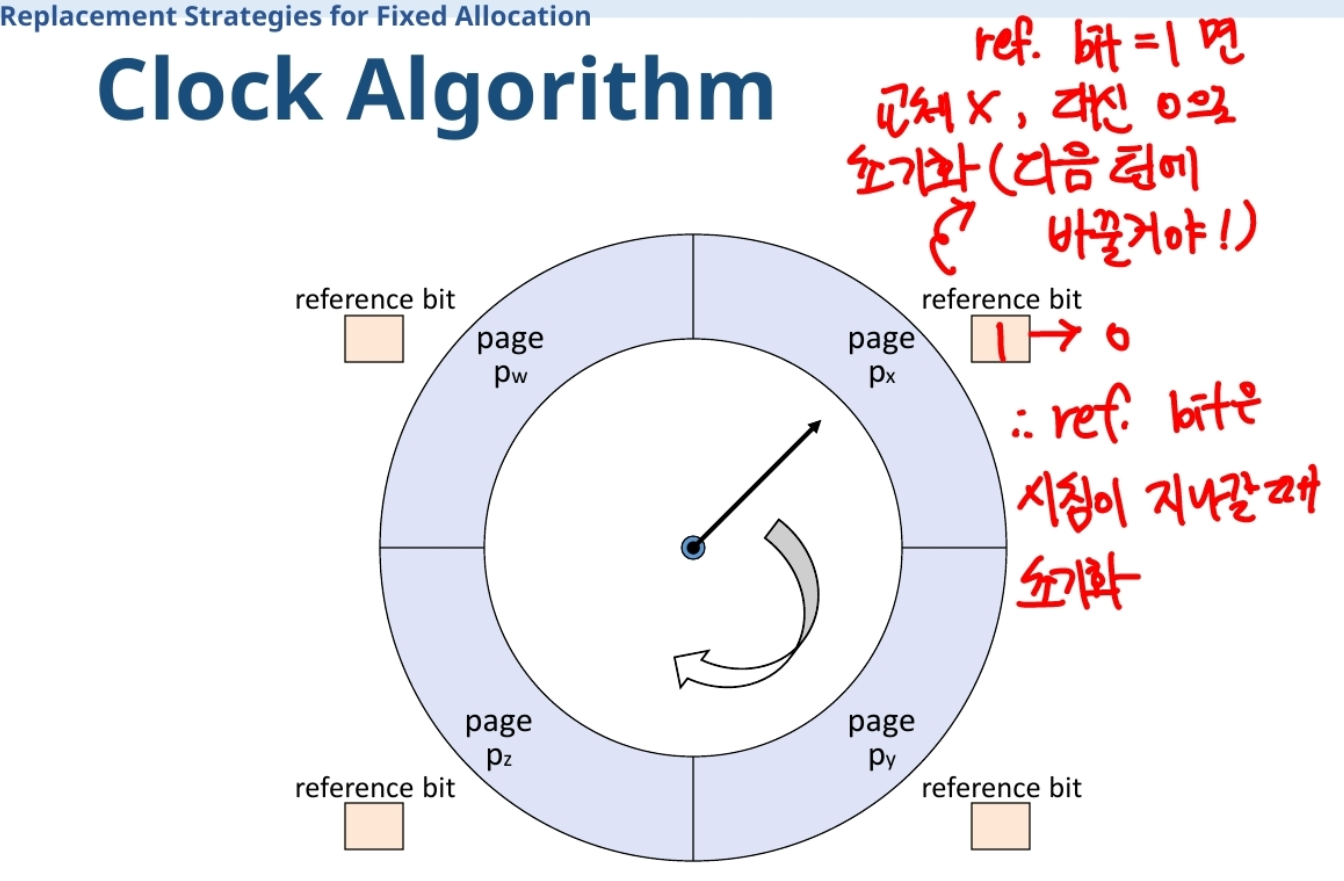
교체전략 중 Clock algorithm이란?
-
Reference bit(r) 사용(Reference bit은 시계바늘이 지나갈 때 초기화)
-
Page frame들을 순차적으로 가리키는 pointer(시계바늘)가 돌아가면서 교체될 page 결정
-
r=0 : 교체 페이지로 결정
-
r=1 : 0으로 초기화 후 pointer 이동
-
-
Locality 반영(reference bit 사용)
-
먼저 적재된 페이지가 교체될 가능성 높음(FIFO와 유사)
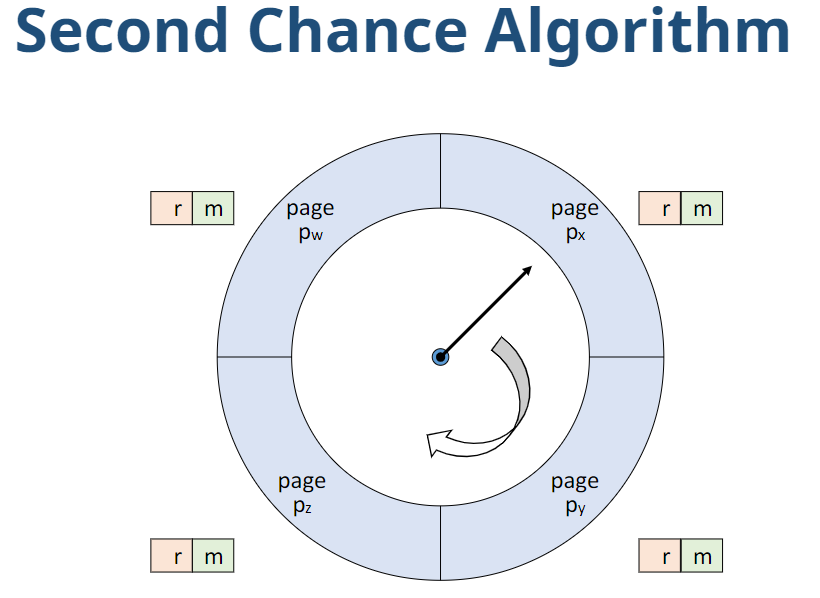
교체전략 중 Second chance algorithm이란?
-
Clock algorithm과 유사하나 update bit(m)도 함께 고려
-
(r,m)의 값에 따른 동작
-
(0,0) : 교체 페이지로 결정
-
(0,1) -> (0,0), write-back 리스트에 추가 후 이동
-
(1,0) -> (0,0) 후 이동
-
(1,1) -> (0,1) 후 이동
-
교체전략 중 WS(Working Set) algorithm이란?
-
working set : 최근 일정시간(Δ) 동안 참조된 page들의 집합(locality 반영)
-
Δ : window size
-
-
시간에 따라 변하는 working set을 메모리에 유지시키는 것(page fault rate 감소)
-
working set은 시간이 지남에 따라 계속 변함(working set transition)
-
Page fault가 없더라도 메모리 반납하는 page가 있을 수 있으므로 working set을 지속적으로 관리해줘야 함(overhead)



교체전략 중 PFF(Page Fault Frequency) algorithm이란?
-
working set size를 page fault rate에 따라 결정하는 것
-
low page fault rate(=long inter-fault time) : 할당된 PF(Page Frame) 수 감소
-
high page fault rate(=short inter-fault time) : 할당된 PF 수 증가
-
-
임계값 τ가 존재(IFT = Inter-Fault Time)
-
IFT > τ: low page fault rate
-
IFT < τ: high page fault rate
-
-
장점
-
page fault 발생 시에만 메모리 상태가 변함(low overhead)
-

교체전략 중 VMIN(Variable MIN) algorithm이란?
-
variable allocation 기반 교체 기법 중 optimal
-
(t, t+Δ] 사이에 해당 페이지가 다시 참조되는지를 고려
-
다시 참조되면 페이지 유지
-
아니면 메모리에서 내림
-
-
실현불가능 : page reference string을 미리 알고 있어야 함

최적의 Δ값은?

Page size가 너무 작으면 어떻게 되나?
-
Large page table, I/O 시간 증가, page fault 증가
-
내부 단편화 감소
Page size가 너무 크면 어떻게 되나?
-
Small page table, I/O 시간 감소, page fault 감소
-
내부 단편화 증가
최근 page size는 왜 커지고 있는가?
-
HW 발전 경향을 보면 CPU가 Disk에 비해 발전 속도가 매우 빠름(gap이 존재) -> 따라서, 시스템 성능향상에 I/O가 bottleneck이 될 가능성 커짐 -> 이에 따라 I/O 시간을 줄여 시스템 전체 성능을 향상시키려고
'CS 기초 > OS' 카테고리의 다른 글
| [OS]CH9. 가상 메모리 (Virtual memory) (0) | 2020.10.20 |
|---|---|
| [OS]CH8. 메모리 관리(Memory management) (0) | 2020.10.19 |
| [OS]CH7. Deadlock(교착상태) (0) | 2020.10.19 |
| [OS]CH6. 프로세스 동기화(Synchronization) & 상호배제(Mutual Exclusion) (0) | 2020.10.16 |
| [OS]CH5. 프로세스 스케쥴링 (0) | 2020.10.12 |



