
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 백준
- 구글 킥스타트
- PYTHON
- 알고리즘
- 네트워크
- 순열
- 코딩테스트
- 킥스타트
- 운영체제
- OS
- 동적프로그래밍
- 코딩
- 프로그래머스
- 브루트포스
- CSS
- AI
- 동적 프로그래밍
- 딥러닝
- nlp
- 프로그래밍
- kick start
- dp
- 파이썬
- 리눅스
- 코딩 테스트
- 그래프
- google coding competition
- linux
- DFS
- BFS
- Today
- Total
목록AI (48)
오뚝이개발자
conda로 가상환경을 만들어 사용하다가 해당 환경의 이름을 변경해주고 싶을 때가 있다. 하지만 아쉽게도 conda 환경의 이름을 rename해주는 방법은 없다. 대신 해당 conda 환경을 clone한 뒤에 기존의 환경을 remove해주어야 한다. 아래의 커맨드를 차례로 입력해주면 된다. conda create --name new_name --clone old_name conda remove --name old_name --all new_name 부분에 새로운 가상환경 이름을, old_name 부분에 제거할 기존의 가상환경 이름을 넣어주면 된다.
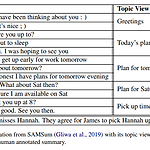 대화 요약 Multi-View Squence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization(2020 EMNLP) 논문 리뷰
대화 요약 Multi-View Squence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization(2020 EMNLP) 논문 리뷰
원논문 링크 : https://arxiv.org/pdf/2010.01672.pdf 본 논문은 dialogue summarization에서 multi-view seq-to-seq model을 제안한 논문이다. 핵심적인 내용으론 unstructured daily chat으로부터 다양한 관점에서의 conversational structure를 추출해 보다 정확한 대화 요약을 생성해낸다는 점이다. 본 모델은 automatic 그리고 human evaluation 모두에서 기존의 SOTA(State-Of-The-Art)를 능가하였다. Dialogue data set의 특징 dialogue data는 기존의 structured date와는 다른 특징을 갖고 있다. informal(사람 간의 chit-chat은 설명..
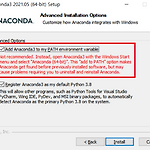 ML개발 GPU 사용 환경 세팅하기(Anaconda, Tensorflow, Keras, CUDA, cuDNN)
ML개발 GPU 사용 환경 세팅하기(Anaconda, Tensorflow, Keras, CUDA, cuDNN)
GPU 환경세팅을 하면서 정말 삽질을 많이 했다....하....이게 참 버전 간 호환성을 맞추는 것도 일이다. 잘못 설치했다가 GPU를 인식하지 못해서 GPU 환경에서 돌리지 못한 경우도 생겼다. 아나콘다 설치 아나콘다는 AI나 데이터 분석에 필요한 여러 라이브러리들을 묶어둔 패키지이다. 이를 다운받아서 사용하면 일일히 필요한 라이브러리들을 설치하지 않아도 되서 매우 편하다. https://www.anaconda.com 에 들어가서 본인의 OS 환경에 맞는 버전을 다운받으면 된다. 중요한 것은 설치 도중 "Add Anaconda3 to my PATH environment variable"에 체크를 반드시 해주어야 한다는 것이다!!!!! conda 가상환경 만들기 conda를 사용해 가상환경을 만들어주어야..
keras를 사용해 멀티 gpu를 사용하는 방법을 알아보자. 해당 메소드는 케라스 2.0.9 버전부터 사용이 가능하니 해당 버전에 맞춰 설치해야 한다. model = Sequential() model.add(layers.LSTM(32, input_shape=(None, float_data.shape[-1]))) model.add(layers.Dense(1)) # multi-gpu 사용 from keras.utils.training_utils import multi_gpu_model model = multi_gpu_model(model, gpus=2) model.compile(optimizer=RMSprop(), loss='mae') history = model.fit_generator(train_gen,..
tensorflow나 keras를 사용해 ML 코드를 돌릴 때 CPU가 아닌 GPU에서 돌아가도록 설정하는 방법에 대해 소개한다. 방법은 크게 2가지 정도가 있는데 본인이 원하는 상황에 따라 맞게 사용하면 된다. 방법 1 : 원하는 부분에만 GPU로 실행하도록 하기 # 텐서를 GPU에 할당 with tf.device('/GPU:0'): a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]) b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]]) c = tf.matmul(a, b) print(c) 위와 같이 with문으로 사용하면 특정 컨텍스트를 묶어 해당 부분만을 특정 GPU로 실행되도록 한다. 이 때, 어떤 GPU를 사용할 ..
 Towards a Human-like Open-Domain Chatbot(Meena) 리뷰
Towards a Human-like Open-Domain Chatbot(Meena) 리뷰
오늘 소개할 논문은 구글 리서치팀에서 발표한 "Towards a Human-like Open-Domain Chatbot"이다. (원논문 링크) Meena라는 이름으로 잘 알려진 2020년도 구글에서 발표한 챗봇에 관한 논문이다. 하지만 사실상 챗봇 모델보다는 evaluation metric을 제안했다는 것에 큰 의의가 있다. 본 논문의 핵심 1. Meena는 end-to-end로 학습된 multi-turn, open-domain 챗봇이다. 2. 다음 토큰의 ppl(perplexity)을 최소화하는 방식으로 학습 3. SSA라는 human evaluation metric을 제안 SSA는 Sensibleness and Specificity Average다. 한마디로, 말이 되는지(sensible) 그리고 g..
 ELECTRA(ICLR 2020) 논문 리뷰
ELECTRA(ICLR 2020) 논문 리뷰
오늘 소개할 논문은 "ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS"이다.(원논문 링크) What is ELECTRA? ELECTRA는 구글 리서치 팀에서 발표한 논문으로 LM의 새로운 pre-training 기법을 제안하였다. ELECTRA는 Efficiently Learning an Encoder that Classifies Token Replacements Accurately의 약자이다. 기존의 MLM(Masked Language Model) 태스트를 통한 pre-training 방식은 많은 연산량을 필요로 한다. 이로 인해 충분한 컴퓨팅 리소스가 없는 연구자들에게 LM을 학습시키기가 점점 어려워지고 있다. ..
케라스에서 optimizer로 RMSprop을 사용하다 보면 위와 같은 에러가 나오는 경우가 많다. 아마 버전 문제이거나 import 형식 때문인 것 같은데(구체적인 원인은 잘 모르겠다...) 하지만 해결법은 알고 있음!!! ㅎㅎ 이런 경우 대부분 아래와 같이 사용했을 경우가 많다. import keras model = ~~~~....# 대충 이 부분에 model definition을 했다고 한다면 model.compile(loss='categorical_crossentropy', optimizer=RMSprop(lr=0.001), metrics=['accuracy']) 이 때 실행을 돌리면 AttributeError: module 'keras.optimizers' has no attribute 'RMS..