
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- kick start
- 동적 프로그래밍
- OS
- 구글 킥스타트
- 코딩
- 순열
- 백준
- 알고리즘
- 프로그래밍
- 동적프로그래밍
- PYTHON
- 킥스타트
- nlp
- 그래프
- DFS
- dp
- BFS
- linux
- 브루트포스
- 코딩테스트
- 코딩 테스트
- google coding competition
- CSS
- 네트워크
- 리눅스
- 프로그래머스
- 파이썬
- 딥러닝
- 운영체제
- AI
- Today
- Total
오뚝이개발자
대화 요약 Multi-View Squence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization(2020 EMNLP) 논문 리뷰 본문
대화 요약 Multi-View Squence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization(2020 EMNLP) 논문 리뷰
땅어 2021. 11. 20. 12:57
원논문 링크 : https://arxiv.org/pdf/2010.01672.pdf
본 논문은 dialogue summarization에서 multi-view seq-to-seq model을 제안한 논문이다. 핵심적인 내용으론 unstructured daily chat으로부터 다양한 관점에서의 conversational structure를 추출해 보다 정확한 대화 요약을 생성해낸다는 점이다. 본 모델은 automatic 그리고 human evaluation 모두에서 기존의 SOTA(State-Of-The-Art)를 능가하였다.
Dialogue data set의 특징
dialogue data는 기존의 structured date와는 다른 특징을 갖고 있다. informal(사람 간의 chit-chat은 설명문이나 논설문처럼 formal하지 않다.), verbose(때로 대화가 장황하게 이어지기도 한다.), repetitive, hesitation, interruption(대화 도중에 끼어드는 것은 dialogue data만이 갖는 특징이다.), scattered information(여러 화자가 대화하며 정보가 산개되어있다)한 특징들이 그러하다. 이런 특성들은 모델이 중요한 부분에 집중하기 힘들게 만든다. 때문에 이러한 특성에 맞는 적절한 요약 method가 필요하다.
View in Conversation

conversation에서의 view는 크게 structured view(topic, stage)와 generic view(global, discrete)으로 구분된다.
- Topic view : 어떠한 topic이 다뤄지는지
- Stage view : 대화의 progression 단계
- Global view : 전체 대화를 하나의 block으로 다룸
- Discrete view : 각 utterance가 하나의 segment로 다뤄짐
그 동안 이루어진 한 가지 view에 focusing해 생성된 요약방식은 다른 view에서의 정보를ㄹ 놓치기 때문에 좀 더 풍성하고 정확한 요약문 생성이 어려웠다. 본 논문에선 위와 같이 서로 다른 여러 view(관점)을 조합해 좀 더 정확한 dialogue 요약문을 생성하려는 시도를 하였다.
전체적인 method
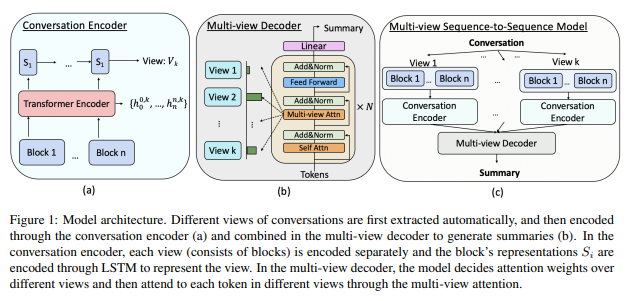
먼저 different view를 추출하고 conversation encoder로 encode한다. 여기서 나온 결과를 종합해 multi-view decoder가 summary를 생성한다.
Encoder
- 각 view가 독립적으로 encode된다.
- block representation Si가 LSTM을 통해 encode되어 view를 represent한다.
Decoder
- 여러 view에 할당할 attention weight 결정
- multi-view attention을 통해 각 view의 token 참조
View Extraction
Topic view
먼저 Sentence-BERT로 sentence representation을 한다. 그 뒤 C99이라는 topic segment algorithm으로 conversation을 topic 별로 분리해 topic view를 추출한다. Conversation C=[u1, u2, ..., um]가 sentence-BERT를 통해 hidden vector로 encode된 뒤 C99 알고리즘을 통해 C'=[b1, b2, ..., bn]으로 변환한다.(u는 utterance를, b는 몇 개의 consecutive한 u가 모인 block을 나타냄) 참고로, C99은 inter-sentence 유사도에 따라 segment를 분리한다.
Stage view
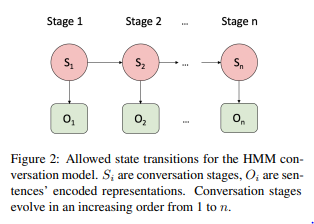
Stage view는 모델이 key information을 담고 있는 stage에 focus하도록 도와준다. 본 논문에서 소개한 바에 따르면 Hidden Markov Model(HMM)을 사용해 stage를 추출하였다.
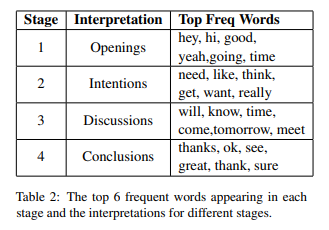
위에서 예시 데이터로 소개한 Table 1의 각 stage별 top frequent words는 아래와 같았다.
Global, Discrete view
Global view는 모든 utterance를 하나의 giant block으로 연결한 것이고, Discrete view는 이와 반대로 각 utterance를 distinct block으로 분리한 것이다.
Multi-view seq2seq model & Dataset
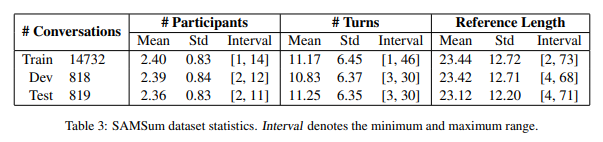
본 논문에선 Transformer based pre-trained BART model을 사용하였다. 데이터로는 SAMSum dataset을 사용하였는데, 이는 14732개의 dialogues(with human-written summary)를 담고 있다.
Baseline
성능 비교 분석을 위해선 아래의 모델들을 사용하였다.
- Pointer Generator
- GPT-2
- Fast Abs RL Enhanced
- BART + Generic view(global, discrete view)
Result
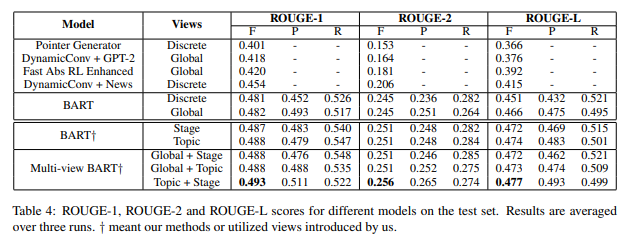
Quantitative result
일단 기본적으로 BART model은 다른 baseline 모델들을 모두 능가하였다. view로서는 stage, topic view가 discrete, global view를 능가하였다. 최종적으로는 topic과 stage view를 종합한 모델이 가장 좋은 성능을 보였고, 이를 통해 두 view가 서로 complementay한 정보를 제공한다는 것을 유추할 수 있다. 추가적인 관측에선 topic view가 stage view보다 좀 더 중요한 역할(prominent)을 한다고 말하고 있다.
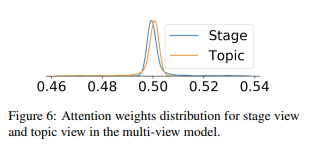
아래 그래프는 attention weight 분포를 나타낸 것인데, topic view의 그래프가 stage보다 살짝 오른쪽으로 치우쳐있는 것을 볼 수 있다.
Human evaluation
연구팀은 Amazon Mechanical Turk를 사용해 human annotator scoring을 진행하였다. 3명의 annotator 점수를 평균하였고 타깃으로는 200개의 random sampled summary 데이터를 대상으로 하였다. 그 결과, multi-view model이 가장 높은 점수를 얻었다.

Impact of Participants and Dialogue Turns
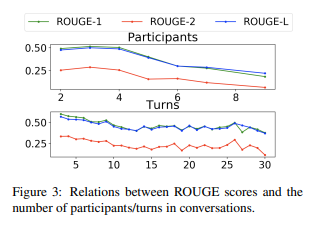
대화에 참여하는 participants와 turn의 수가 증가하면 rouge score는 하락하는 경향을 보인다. 이것이 longer conversation summarization이 어려운 이유이다. 화자가 많아지고, turn이 많은 대화는 훨씬 더 많은 정보를 processing해 요약해야 하기 때문에 더 어렵다.
Challenges in Dialogue Summarization
1. Informal : typo, abbreviation, slang, emoji...
2. Multiple participants : 다중 화자를 명확히 구분해야 하고, 각각의 style이나 content를 잘 파악해야 한다.
3. Multiple turns : long document summarization처럼 처리해야 할 정보가 많다.
4. Referral & Coreference : 사람들은 주로 서로를 refer하거나 coreference를 사용하는데 대화 내에서 이것들이 각각 무엇을 지칭하는지에 대해 정확히 파악해야 한다.
5. Repetition, Interruption : 대화를 나누던 도중 끼어드는 것은 dialogue data만의 특성
6. Negation, rhetorical question
7. Role and Language change : 화자의 역할이 질문자에서 답변자로 바뀌기도 한다.
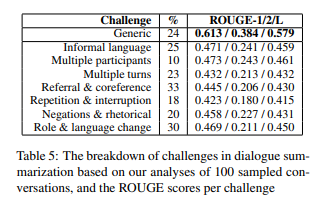
아래 Table5는 test set에서 100개의 데이터를 random sample한 것 중 각 challenge의 비율을 나타낸 것이다. 참고로, 하나의 데이터가 여러 개의 challenge에 label될 수 있다. Referral & Coreference의 비율이 가장 크고, Role & language change가 그 다음으로 많은 비율을 차지한다.
Error Analysis
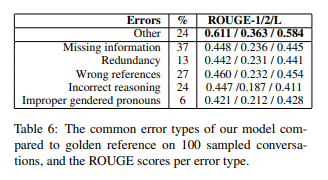
본 논문에선 생성된 요약문에서 발생한 error type을 다음과 같이 분류하였다.
1. Missing information : reference에서 언급된 content가 generated summary에 없는 경우
2. Redundancy : summary에 언급된 content가 reference에 없는 경우
3. Wrong reference : action, location 등을 다른 speaker와 매칭한 경우
4. Incorrect reasoning : summary가 dialogue 속 relation을 잘못 파악해 wrong conclusion을 내는 경우
5. Improper gendered pronoun
아래는 이들 에러 타입의 비율을 나타낸 표이다. 가장 큰 비율을 차지하는 것은 Missing information에러이다.
Challenge-Error Corelation
모든 challenge는 missing information error과 높은 상관관계를 보인다. incorrect reasoning error는 role&language change, referral&coreference와 높은 상관관계를 보인다. 즉, 많은 화자 간의 잦은 reference 사용은 incorrect reasoning의 발생을 증가시켜 대화 요약을 어렵게 만든다.
'AI > Deep Learning Paper Review' 카테고리의 다른 글
| Forward-Forward Algorithm 논문 리뷰 (0) | 2023.02.26 |
|---|---|
| RepSum : Unsupervised Dialogue Summarization based on Replacement Strategy(ACL 2021) 논문 리뷰 (0) | 2022.01.04 |
| Towards a Human-like Open-Domain Chatbot(Meena) 리뷰 (0) | 2021.11.04 |
| ELECTRA(ICLR 2020) 논문 리뷰 (1) | 2021.10.27 |
| BERT(NAACL-HLT 2019) 논문 리뷰 (0) | 2021.10.08 |



