
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 파이썬
- BFS
- 그래프
- 코딩 테스트
- linux
- 네트워크
- 동적 프로그래밍
- 알고리즘
- 프로그래머스
- kick start
- 구글 킥스타트
- 백준
- 프로그래밍
- CSS
- google coding competition
- 리눅스
- PYTHON
- 동적프로그래밍
- 순열
- 코딩테스트
- 운영체제
- dp
- AI
- 브루트포스
- 킥스타트
- DFS
- nlp
- 딥러닝
- 코딩
- OS
- Today
- Total
오뚝이개발자
RepSum : Unsupervised Dialogue Summarization based on Replacement Strategy(ACL 2021) 논문 리뷰 본문
RepSum : Unsupervised Dialogue Summarization based on Replacement Strategy(ACL 2021) 논문 리뷰
땅어 2022. 1. 4. 21:15
paper link : https://aclanthology.org/2021.acl-long.471.pdf
Overview
Dialogue summarization에서 일반적인 text summarization과 비교했을 때 어려운 점은 바로 training data가 부족하다는 것이다. 이 논문은 이러한 문제를 unsupervised 학습으로 해결하고자 시도하였다. 논문의 핵심 아이디어는 다음과 같다.
Superior summary approximates a replacement of the original dialogue, and they are roughly equivalent for auxiliary tasks.
즉, 좋은 요약본은 원문의 데이터들을 충분히 가지고 있으므로 여러 task에서 원래의 dialogue를 충분히 대체할 수 있다는 점에 착안하여 요약의 성능을 높이는 것이다.
How it works?

그럼 이러한 RepSum은 어떤 방식일까? 개략적인 로직은 위의 그림과 같다. 먼저 dialogue를 기반으로 summary를 생성한다. 그 후 original dialogue와 summary에서 각각 n번째 utterance를 predict한다. 이 둘의 차이를 최소화 하도록 학습을 진행시킨다. 조금 더 디테일하게는 아래의 그림과 같이 구성된다.

dialogue로부터 extractive, abstractive 두 가지 방식으로부터 각각의 summary를 만들어 낸다. 그 후 이들을 가지고 n번째 utterance에 대한 generation과 classification task를 수행한다. generation task는 말 그대로 n번째 utterance를 생성해내는 것이고, classification task는 n번째 utterance를 주어진 선택지 중에 고르는 task이다. 위 그림에서 TG가 바로 Text Generation task를, TC가 Text Classification task를 가리킨다.
그럼 이렇게 만들어진 결과를 가지고 최적화를 진행해야 한다. 그림에서 가장 아래 박스 두 개가 있는데 이는 각각 원문으로부터의 task 수행 결과와 요약문으로부터의 task 수행 결과 사이에 차이를 구해 이를 최소화하는 것을 나타낸다. 논문에선 이를 KL divergence를 사용해 구했다.
2개의 Task
Text Generation(TG)
TG에서의 목표는 n번째 utterance를 생성해내는 것이다. 이를 위해 논문에선 Encoder로 bi-directional LSTM을, Decoder로는 uni-directional LSTM을 사용하였다. 전체 dialogue를 concatenate하여 document로 인코딩하고, attention을 활용해 n번째 utterance를 디코딩하였다. TG에서의 loss function은 아래와 같이 된다.

Text Classification(TC)
TC에서의 목표는 n번째 utterance로 가장 적절한 것을 K개의 후보군 중에 select하는 것이다. Encoder로는 bi-directional LSTM을 사용하였고, 이는 classification task이므로 decoder는 필요하지 않다. dialogue 원문과 summary를 encoder를 통과시켜 만든 representation을 h라고 하고 candidate들을 encoder를 통과시켜 만든 representation을 c라고 한다면 h와 c를 concatenate한 뒤 classifier를 거치도록 구성하였다. TC에서의 loss는 아래와 같다.

Unsupervised summarization
논문에선 추출요약과 생성요약 두 가지 방식 모두에 대해 실험을 진행하였다.
Extractive
추출 요약으로는 SummaRunner(Nallapati et al., 2017)와 유사한 방식으로 sentence binary classification을 수행하였다. dialouge 내에서 각 문장마다 binary label을 부여하는 것인데 요약문에 포함시키고자 하는 문장은 1로, 그렇지 않은 문장은 0으로 분류하는 것이다. label이 없기 대문에 이러한 결과를 TG, TC task를 통해 요약 성능을 최적화 하였다.
Abstractive
일반적인 encoder-decoder 구조를 사용해 생성 요약을 구성하였다. softmax probability distribution으로부터 각 단어를 sampling하였다. 그런데 이러한 text 생성 시에 통상 argmax를 사용해 확률이 가장 높은 단어를 선택하는 방식을 사용하는데 이는 non-differentiable한 특성을 갖는다. 그러나 TC, TG task를 거친 후에 역전파를 통해 파라미터를 갱신하는 최적화 과정을 거치도록 해줘야 하므로 본 논문에선 ST Gumble Estimator라는 것을 사용하였다.(짧게 설명하자면 이처럼 argmax를 사용해 미분불가능한 특성을 갖는 모델에 사용할 수 있는 방법이다)
Dataset
- AMI dataset : meeting dataset in English
- 100 hours of meeting recordings
- high-quality
- manually produced transcription, dialogue acts, topic segmentation, extractive/abstractive summaries
- Justice dataset : court debate records in Chinese
- 30,000 dispute cases
- multiple roles(i.e., judge, plaintiff, defendant)
- fact description(판결에 대한 판사의 요약)을 expected summary로 사용
Result
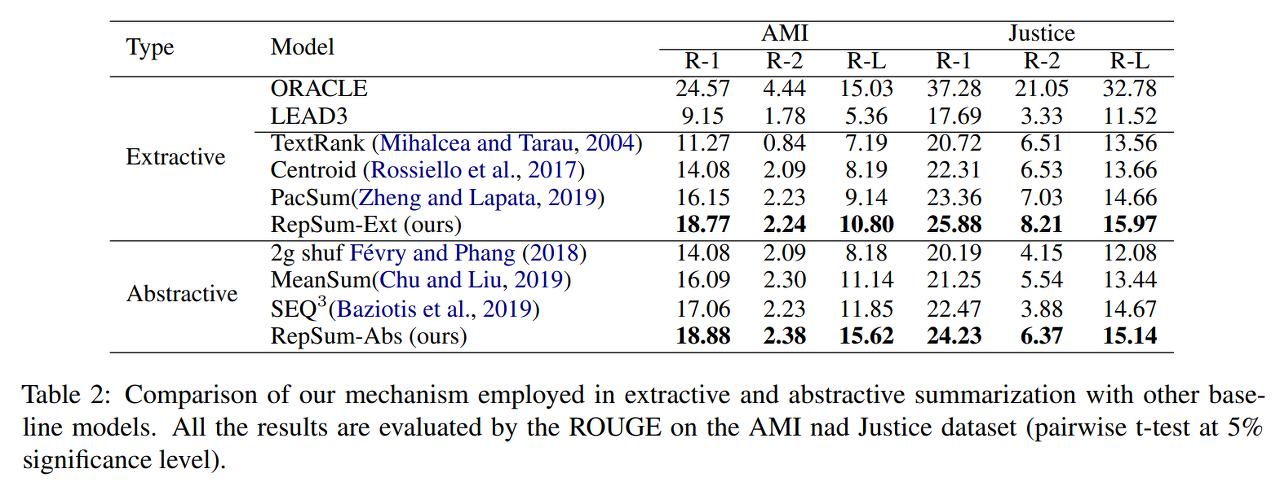
ORACLE은 ROUGE score를 최대화하는 방향으로 greedy하게 추출한 것이다. 이를 upper bound로 두고 비교 가능하다. LEAD n이라는 것은 첫 n개의 문장을 추출한 것을 말한다. 즉 표에서 LEAD3는 처음 3개의 문장을 추출해 요약문을 구성한 것이다.
Human evaluation
여기서의 평가기준은 relevance와 fluency다. 즉, 생성된 요약문이 얼마나 원문과 유관하고 유창한지(자연스러운지)를 보는 것이다. 각 데이터셋마다 100개의 샘플을 선정하여 6명의 대학원생 평가자들이 평가를 진행했다.
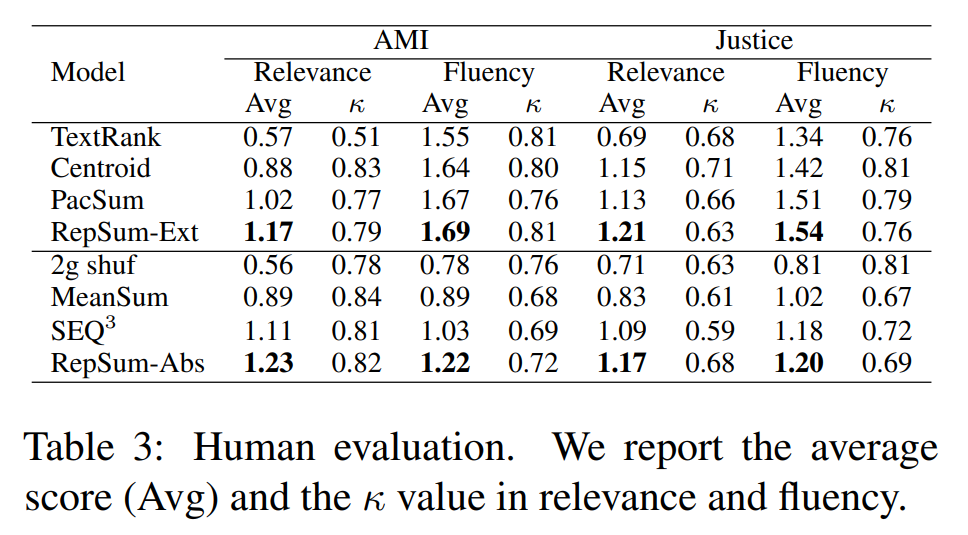
Ablation study

표를 보면 TC보다도 TG task가 모델의 전반적인 성능에 더 큰 영향을 주는 것을 볼 수 있다.
'AI > Deep Learning Paper Review' 카테고리의 다른 글
| Forward-Forward Algorithm 논문 리뷰 (0) | 2023.02.26 |
|---|---|
| 대화 요약 Multi-View Squence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization(2020 EMNLP) 논문 리뷰 (0) | 2021.11.20 |
| Towards a Human-like Open-Domain Chatbot(Meena) 리뷰 (0) | 2021.11.04 |
| ELECTRA(ICLR 2020) 논문 리뷰 (1) | 2021.10.27 |
| BERT(NAACL-HLT 2019) 논문 리뷰 (0) | 2021.10.08 |



