
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬
- kick start
- 순열
- CSS
- PYTHON
- 킥스타트
- AI
- 코딩 테스트
- OS
- BFS
- 코딩테스트
- dp
- 구글 킥스타트
- 동적프로그래밍
- 운영체제
- 브루트포스
- 프로그래밍
- 리눅스
- 백준
- 네트워크
- 그래프
- 프로그래머스
- google coding competition
- 코딩
- linux
- 알고리즘
- 동적 프로그래밍
- nlp
- DFS
- 딥러닝
- Today
- Total
오뚝이개발자
Forward-Forward Algorithm 논문 리뷰 본문
오늘 소개할 논문은 Geoffrey Hinton의 “The Forward-Forward Algorithm: Some Preliminary Investigations”이다. 2022 NIPS talk에서 다루어졌던 논문으로 22년 12월에 arXiv에 공개된 따끈따끈한 논문이다. 힌튼은 현재 딥러닝 학습의 근간을 이루는 역전파(Backpropagation) 알고리즘의 초기 연구에 참여했던 인물이다.
Backpropagation(이하 BP)은 오늘날 여러 AI 모델들의 learning procedure에 사용되는 중요한 알고리즘이다. 하지만 컴퓨터 과학자이면서 인지심리학자이기도 한 힌튼은 실제 우리 대뇌 피질의 학습 과정이 BP와 유사하지 않다는 점을 지적하면서 새로운 Forward-Forward algorithm(이하 FF)을 제안한다. 간단히 말하자면, BP는 추론(inference)과 학습(learning)의 과정이 나뉘어져있는데 인간은 이 두가지가 동시에 즉각적으로 이루어진다는 점에 착안한 것이다. 최근 FF 알고리즘에 대해 BP를 대체할 수 있는가에 대해 많은 논의들이 이루어지고 있는데, 분명한 것은 Artificial General Intelligence(AGI)로 나아가기 위해서는 이처럼 추론을 하면서 동시에 학습을 해서 자동적, 점진적으로 발전해 나아가는 모델의 등장이 필수적이란 것이다.
What is FF algorithm?
FF 알고리즘은 BP와 같이 AI 모델의 learning procedure에 대해 제안된 또 다른 방법이다. 논문에 따르면 FF 알고리즘에는 두 개의 forward pass가 존재한다. positive data(i.e., real data)에 대해 진행되는 positive pass 그리고 negative data(can be generated by perturbing positive data)에 대해 진행되는 negative pass이다. FF 알고리즘에서 각 layer는 고유의 objective를 갖고 있는데 positive data에 대해서는 high goodness를, negative data에 대해서는 low goodness를 갖도록 하는 것이다. Goodness라는 것은 positive data를 얼마나 positive data로 분류하는지를 나타내는 정도이다. BP의 loss function과 유사한 개념인데 뒤에서 더 자세히 설명하겠다. 본 논문에선 layer의 sum of squared activities를 goodness로 사용하였는데 저자는 아직 다른 goodness 정의에 대해 많은 가능성이 있다고 말한다.

Limitations of BP
BP는 neural network의 전파가 최종 layer를 거쳐 최정 output을 낼 때까지 기다렸다가 이를 다시 역전파를 통해 가중치를 갱신한다. 하지만, 저자는 실제 우리의 뇌가 BP 알고리즘처럼 학습한다는 명확한 증거가 없을뿐더러 오히려 뇌영상장치를 통해 학습 시 active한 부분들을 살펴보았을 때 loop를 형성하는 부분들이 관측된다고 말한다. 정확히는 아래와 같이 쓰여있다.
The top-down connections from one cortical area to an area that is earlier in the visual pathway do not mirror the bottom-up connections as would be expected if backpropagation was being used in the visual system. Instead, they form loops in which neural activity goes through about half a dozen cortical layers in the two areas before arriving back where it started
즉 실제 perceptual system에서 인간은 추론(inference)과 학습(learning)을 동시에 진행하고 여기엔 backpropagation을 위한 time-out이 없다는 것이다. 바꿔말하면, 우리 뇌의 시냅스들은 추론을 하면서 동시에 각각의 unit이 즉각적인 학습을 진행하는 것이지 말단이 output을 낼때까지 기다렸다가 학습이 진행되지 않는다는 것이다. (저자는 FF 알고리즘의 또 다른 특징으로 neural activity를 BP 처럼 store할 필요가 없다는 점을 언급하였는데 이 부분은 사실 읽어도 이해를 잘 못하겠다...) 저자는 논문에서 FF 알고리즘은 특히 low power H/W 환경에서 BP를 능가할 수 있을 것이라고 말한다.
How it works
앞서 설명한대로 BP가 forward, backward 두 개의 pass가 존재하는 것과 달리 FF 알고리즘에는 두 개의 pass가 존재한다. 하나는 positive data(real data)에 대해 작동하는 positive pass, 다른 하나는 negative data에 대해 작동하는 negative pass이다. 둘의 동작원리는 동일하지만 positive pass에선 positive data에 대해 goodness를 높이는 방향으로, negative pass에선 negative data에 대해 goodness를 낮추는 방향으로 가중치 updata가 진행된다. 쉽게 말해, threshold 값을 설정해두고 positive data에 대해선 goodness > threshold가 되도록, negative data에 대해선 goodness < threshold가 되도록 학습을 진행한다.
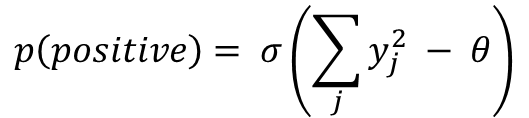
식으로는 위와 같이 logistic function σ를 이용해 positive data가 주어졌을 때 positive or negative로 올바르게 분류하는 것이 목적이다. j는 j번째 layer를 y를 그 layer의 hidden unit을 그리고 θ는 threshold를 의미한다.
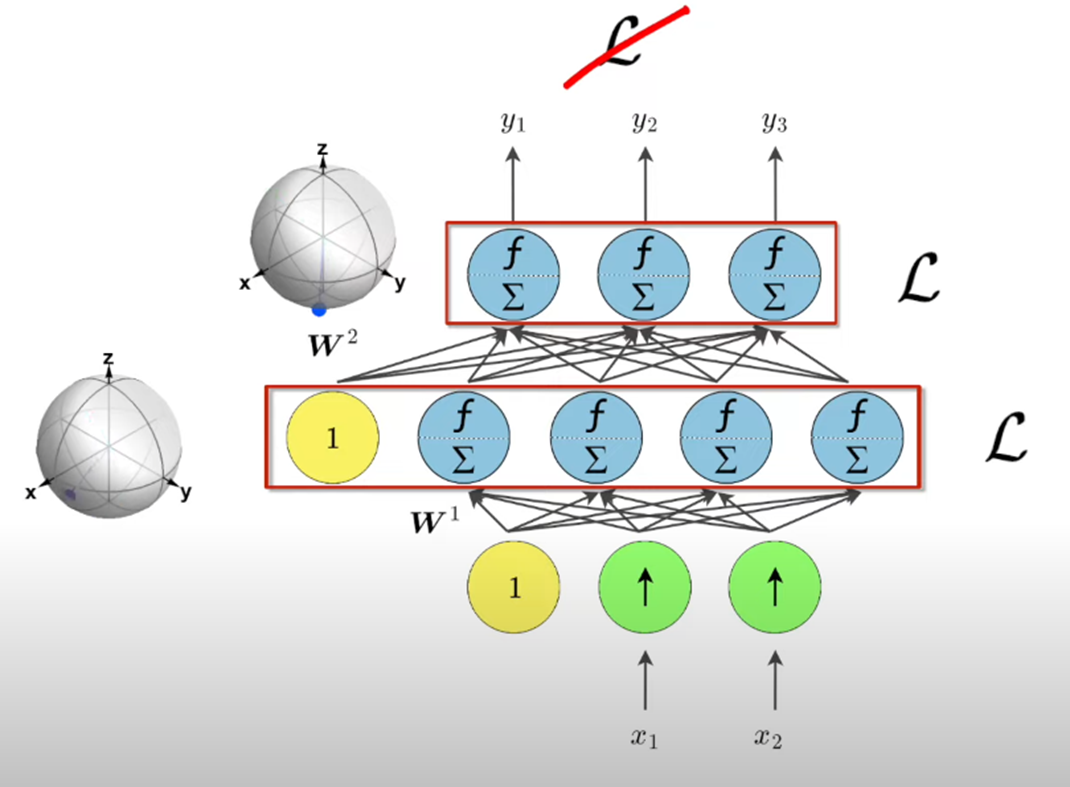
위 그림에서 BP가 최종 layer를 지나고나서의 loss를 이용하여 최적화하는 것과 달리 FF는 각 layer-level에서의 loss function(goodness)를 최적화한다. 또한 각 layer를 vector로 간주하여 이 vector의 size를 positive data에 대해선 increase하는 방향으로 negative data에 대해선 decrease하는 방향으로 가중치를 갱신한다.
Experiments with FF
저자는 MNIST dataset을 사용해 실험을 진행하였다. 해당 데이터셋은 이미 유명하고 특히 BP를 이용한 여러 모델들에 대한 성능이 잘 나온 것이 입증된 데이터셋이기에 새로운 learning procedure이 제대로 작동하는지 시험하기에 적합하다고 생각되어 선정하였다고 한다.
Unsupervised Example
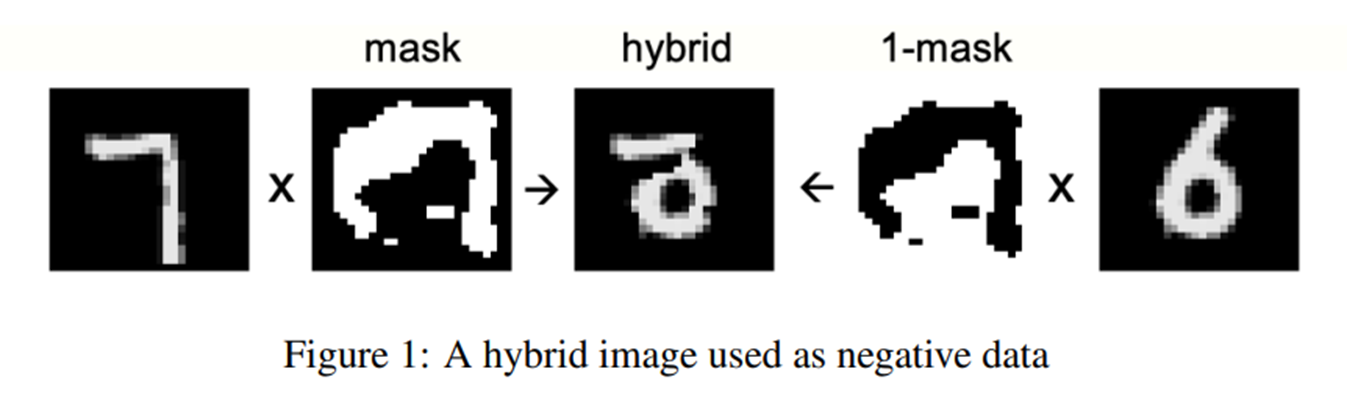
저자는 unsupervised 예시에 대해 MNIST dataset을 이용하여 위와 같이 negative data를 만들었다고 한다. 먼저 positive data인 7과 임의로 생성한 mask를 곱하고 다른 데이터 6을 준비해 이를 reversed된 1-mask와 곱한 뒤 둘을 더해 negative data를 만든다. 이를 이용해 4개의 FC layer를 가진 neural network에서 100에폭동안 학습하여 1.37%의 error rate를 기록했다고 한다. 저자는 실험에서 마지막 3개의 hidden layer의 normalized vector를 sofrmax 함수의 input으로 사용하였다고 하는데, 약간의 트릭같기도 하지만 이는 BP처럼 뒷단에서의 학습 정보가 앞단의 layer에 전달될 수 없으니 모든 layer-level에서의 goodness를 참고해 결과를 얻어내려고 한 듯하다.
Supervised Example
supervised example의 경우 unsupervised처럼 mask를 만들필요가 없어 더 쉽다. 논문에선 label 정보를 input data에 포함시켜 학습을 진행했다. MNIST data의 first 10 pixels를 label을 나타내는 vector로 사용하였다고 한다. positive data는 이 10개의 픽셀이 correct label로 되어있고, negative data에 대해선 incorrect label로 만들었다고 한다. Inference 시에는 이 10개의 픽셀을 neutral label로 초기화한다. 그리고 각 label(손글씨 데이터셋이니 이 경우 0~9)에 대해 추론을 한 뒤 가장 높은 goodness를 보인 숫자로 최종 output을 결정한다. 이처럼 모든 label에 대해 label의 갯수만큼 inference하는 작업이 필요하다는 것이 FF 알고리즘의 단점인 듯하다. 논문에선 4개의 FC layer에서 60 에폭동안 학습하여 1.36%의 error rate를 기록했다고 한다. 참고로 BP는 20에폭만에 같은 성능을 도달하였다.

Result on CIFAR-10 dataset
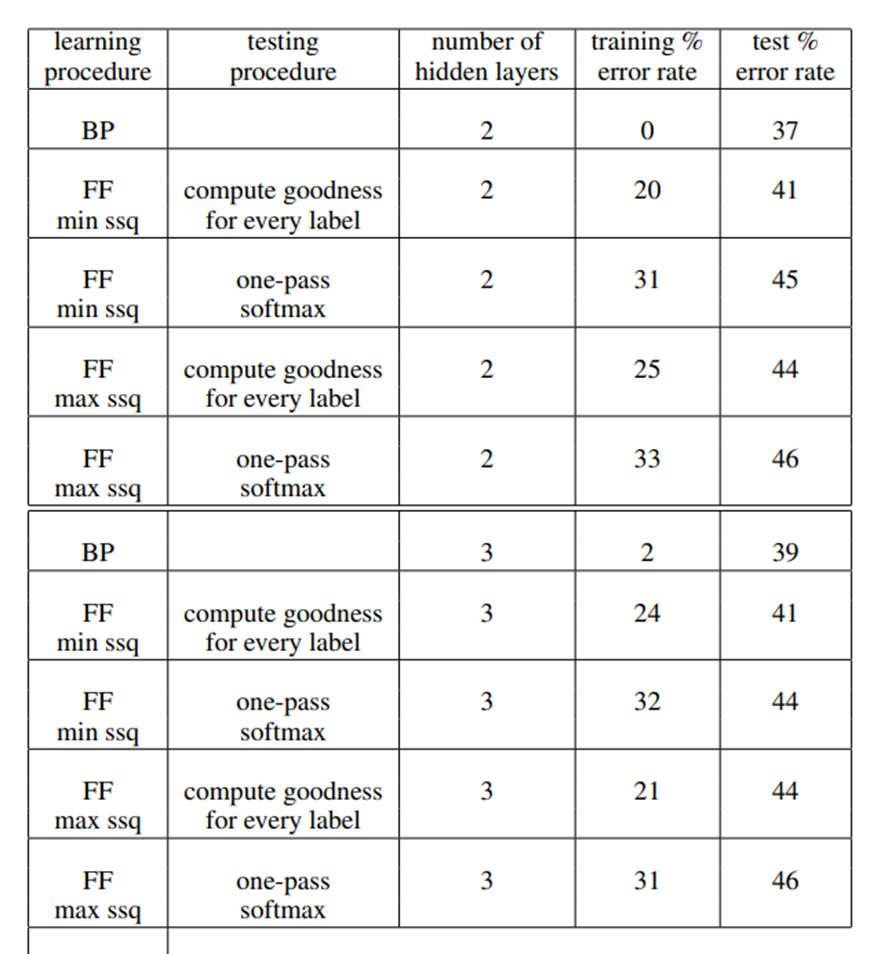
저자는 CIFAR-10 데이터셋에 대해서도 실험을 하였는데, MNIST와 마찬가지로 이미지 분류 데이터셋이다. 위 표에서 BP는 backpropagation, FF는 forward-forward 알고리즘이다. compute goodness for every label이 supervised 방식, one-pass softmax가 unsupervised 방식이다. ssq는 sum of squared activity라는 goodness metric인데 min ssq는 이를 최소화하는 것이고, max ssq는 이를 최대화하는 방향으로 학습을 진행한 것이다. 표를 보면 training error는 BP에 비하면 FF 알고리즘이 아주 높지만, 주목할만한 부분은 test error에 대해서는 BP에 비해 크게 성능이 차이나지 않는다는 점이다.
FF 알고리즘이 과연 BP를 대체할 수 있을지는 아직 확실히 모르겠다. 하지만 error rate를 보았을 때 학습이 진행되고 있다는 것이 새로운 학습 알고리즘으로서의 가능성을 보여준다고 생각된다. 저자도 언급했듯이 더 나은 goodness function에 대한 정의, large model에서의 성능과 같이 연구되어야 할 것이 많이 남아있다.



